
Los análisis psicométricos tienen por objetivo entregar indicadores de rendimiento individual de los estudiantes en cada una de las pruebas aplicadas, tanto a nivel de puntaje, como de clasificación en Estándares de Aprendizaje y Resultados de Aprendizaje.
Estos análisis se realizan sobre la base de lineamientos internacionales (AERA, APA y NCME, 2014) que aseguran la estandarización de los procesos, y están sujetos a estrictos controles de calidad, incluyendo un procesamiento en paralelo por al menos dos profesionales, lo que permite detectar inconsistencias y de haberlas se verifican y ajustan de manera inmediata.
Los modelos que orientan los análisis psicométricos de las pruebas a gran escala, en general, son la Teoría Clásica de los Test (TCT) y la Teoría de Respuesta al Ítem (TRI).
Teoría Clásica de los Test
Se trata de la teoría dominante en la construcción y análisis de los test. Es relativamente fácil construir test que cumplan los mínimos que pide este paradigma. También es relativamente sencilla la evaluación del propio test en cuanto a los parámetros citados: confiabilidad y validez. Tiene su origen en los trabajos de Spearman a principios del siglo XX. Luego, en 1968, los investigadores Lord y Novick llevan a cabo una reformulación de esta teoría y abren paso al nuevo enfoque de la TRI.
Esta teoría se basa en el modelo lineal clásico. Este modelo fue propuesto por Spearman, y consiste en asumir que la puntuación que una persona obtiene en un test, que denominamos su puntuación empírica, y que suele designarse con la letra X, está formada por dos componentes. Por un lado, encontramos la puntuación verdadera del sujeto en el test (V), y por otro, el error (e). Se expresa de la siguiente manera: X = V + e.
Spearman añade tres supuestos a esta teoría:
-Primero, definir la puntuación verdadera (V) como la esperanza matemática de la puntuación empírica: Se trata de la puntuación que tendría una persona en un test si lo hiciera un número infinito de veces.
-No existe relación entre la cantidad de puntuaciones verdaderas y el tamaño de los errores que afectan a esas puntuaciones.
-Finalmente, los errores de medida en un test no están relacionados con los errores de medida en otro test diferente.
Para culminar esta teoría, Spearman define los test paralelos como aquellos test que miden lo mismo pero con distintos ítems.
Teoría de Respuesta al Ítem
La teoría de respuesta a los ítems (TRI) nace como complemento de la teoría de los test clásica. Dicho de otra manera, la TCT y la TRI podrían evaluar un mismo test, al igual que establecer una puntuación o una relevancia para cada uno de los ítems, lo que a su vez nos podría dar un resultado distinto para cada persona. Por otro lado, señalar que la TRI nos daría un instrumento mucho mejor calibrado.
La TRI tiene varios supuestos, plantea que cualquier instrumento de medición debe estar en consonancia con una idea, en otras palabras, existir una relación funcional entre los valores de la variable que miden los ítems y la probabilidad de acertar estos. Esta función se denomina Curva característica del ítem (CCI).
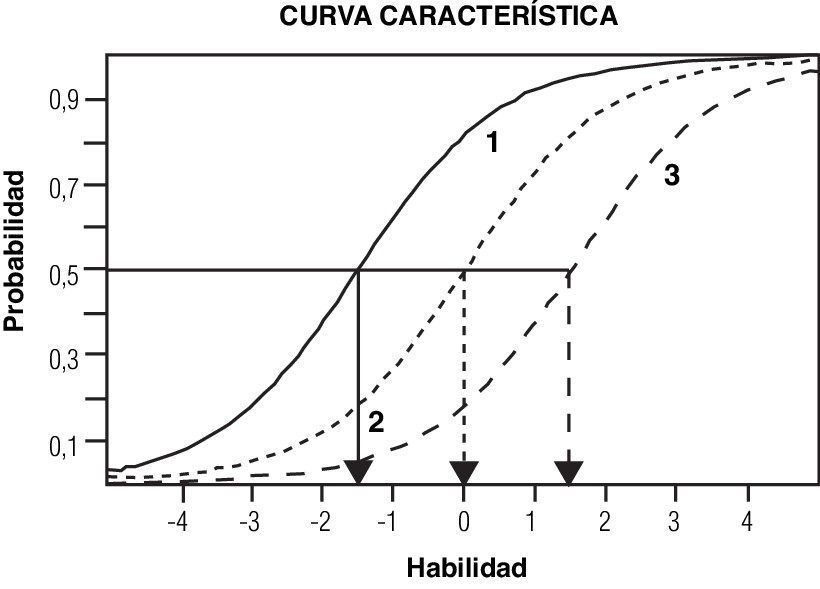
La TRI, a diferencia de la TCT, propone algo que puede parecer muy lógico, los ítems más difíciles serían aquellos que solo contestan las personas más inteligentes. Por otro lado, un ítem que contestan todas las personas bien no es válido porque no tendría ningún poder para discriminar. Dicho de otra manera, no daría ningún tipo de información.
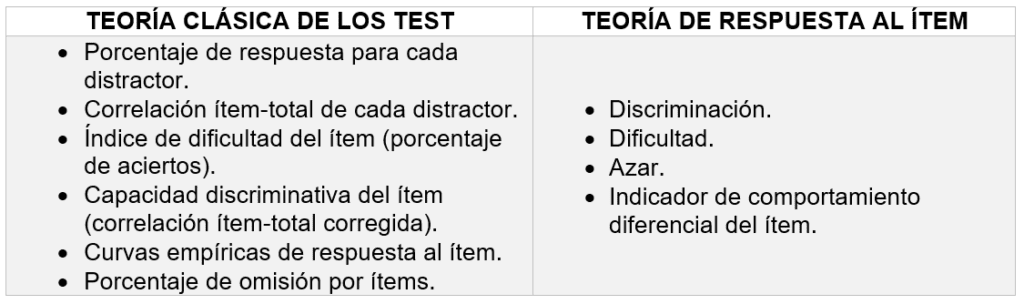
Para las preguntas cerradas de selección simple con múltiples opciones, cada teoría permite establecer ciertos indicadores. Los mismos se evidencian en la tabla 1:
Tabla 1: Indicadores suministrados por la TCT y TRI
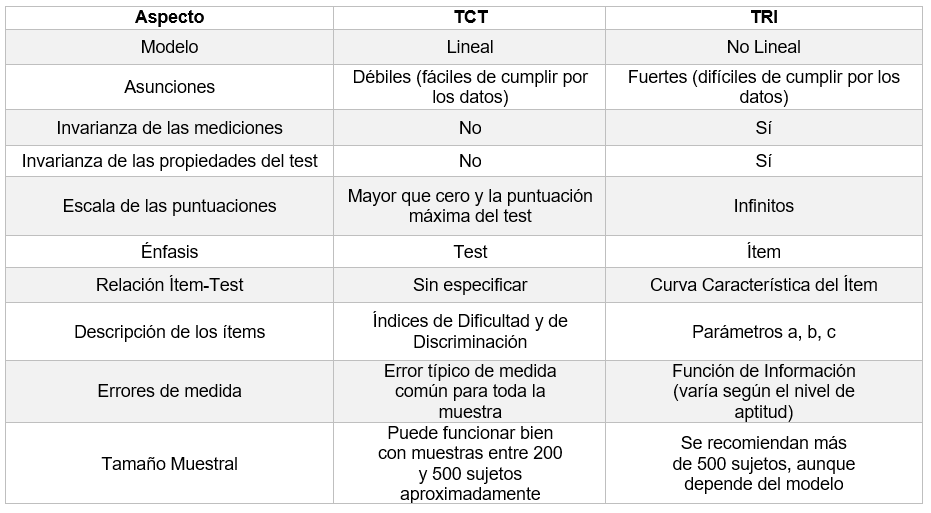
Entre el enfoque clásico y la TRI, según Muñiz (1997), se presentan ciertas similitudes y diferencias, se muestran en la tabla 2.
Tabla 2 Diferencias entre la TCT y la TRI
Para obtener los resultados se utiliza fundamentalmente el modelo de medición Teoría de Respuesta al ítem (TRI), debido a que este se centra en las propiedades de los ítems individuales, permitiendo establecer la probabilidad de contestar correctamente a cada pregunta de acuerdo al nivel de habilidad del estudiante. En particular, el modelo TRI de tres parámetros, permite estimar la habilidad de un estudiante, basándose en la probabilidad de respuesta correcta según tres características propias de las preguntas: dificultad, discriminación y azar.
Modelo RASCH
La denominada Teoría Clásica de los Tests ha sido el principal modelo psicométrico empleado en la construcción y análisis de tests. Sin embargo, sus limitaciones han llevado a la propuesta de modelos alternativos, como lo es el modelo de Rasch, propuesto en 1960 por el matemático danés Georg Rasch que permite, dado un buen ajuste de los datos, la medición conjunta de personas e ítems en una misma dimensión o constructo. Este modelo se fundamenta en los siguientes supuestos:
-El atributo que se desea medir puede representarse en una única dimensión en la que se situarían conjuntamente las personas y los Ítems.
-El nivel de la persona en el atributo y la dificultad del Ítem determinan la probabilidad de que la respuesta sea correcta. Si el control de la situación es adecuado, esta expectativa es razonable y así debe representarla el modelo matemático elegido.
Rasch utilizó la función logística para modelar una relación, estableciendo que el cociente entre la probabilidad de una respuesta correcta y la probabilidad de una respuesta incorrecta de un ítem es una función de la diferencia en el atributo entre el nivel de la persona y el nivel del ítem. Siendo Pis la probabilidad de una respuesta correcta, ?s el nivel de la persona y ?i el nivel del ítem.
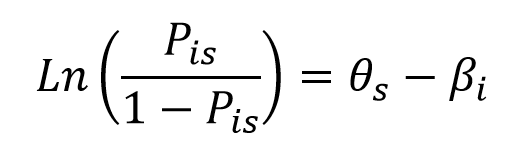
Así, cuando una persona responde a un ítem equivalente a su umbral de competencia, tendrá la misma probabilidad de una respuesta correcta y de una respuesta incorrecta, allí el cociente de las probabilidades es igual a 1, (Pis /1 – Pis= 0,50/0,50). En este caso, el logaritmo natural de uno es igual a cero, reflejando así que la dificultad del Ítem es equivalente al nivel de competencia de la persona (θs – βi= 0).
Por otro lado, si la competencia del sujeto es mayor que la requerida por el ítem (θs – βi > 0), la probabilidad de una respuesta correcta será mayor que la de una respuesta incorrecta. De manera contraria, si la competencia del sujeto es menor que la requerida por el Ítem (θs – βi <0), la probabilidad de una respuesta correcta será menor que la de una respuesta incorrecta.
Significado de las estadísticas en una prueba
-Mediana de la calificación: implica de manera indirecta que la mitad de los estudiantes tienen una calificación inferior a este valor.
-Desviación estándar: es una medida de la dispersión de las calificaciones alrededor de la media, en otras palabras, qué tan alejados se encuentran los resultados con respecto a la media.
-Sesgo: una medida de la asimetría de la distribución de calificaciones. Cero implica una distribución perfectamente simétrica, los valores positivos indican una ‘cola’ a la derecha y los valores negativos una ‘cola’ a la izquierda.
– Kurtosis: es una medida de que tan plana está la distribución. Se debe obtener un valor en el rango entre 0 y 1. Un valor mayor que 1 indica que el examen no está discriminando muy bien entre los estudiantes muy buenos (o los muy malos) y aquellos que son promedio.
-Coeficiente de consistencia interna: para una evaluación al obtener cualquier valor sobre 75% es satisfactorio. Un valor bajo (menor a 50%) indica que algunas de las preguntas no son muy buenas para discriminar entre estudiantes de diferente habilidad y por esto las diferencias entre las puntuaciones totales están en gran medidas asociadas al azar.
-Tasa de error: estima el porcentaje de la desviación estándar que se debe a efectos aleatorios en lugar de diferencias genuinas de la habilidad entre los estudiantes. Valores de tasa de error superiores al 50% no pueden considerarse satisfactorios; implican que menos de la mitad de la desviación estándar se debe a diferencias en habilidad y que el resto son efectos aleatorios. Se relaciona con el coeficiente de consistencia interna.-Índice de discriminación: indica qué tan efectiva es la pregunta para clasificar a los estudiantes más capaces de los menos capaces. Para tener una adecuada discriminación, se debe tener entre un 30% y un 50%, menor al 30% la discriminación se vuelve débil.
-Eficiencia de discriminación: estima qué tan bueno es el índice de discriminación en relación con la dificultad de la pregunta. La discriminación máxima requiere un índice de facilidad que esté en el rango del 30% al 70%.
Referencias
American Educational Research Association (AERA), American Psychological Association (APA), & National Council on Measurement in Education (NCME), 2014. Standards for educational and psychological testing. Washington: American Educational Research Association.
Agencia de Calidad de la Educación (ACE) www.agenciaeducacion.cl
CENTRO DE MEDICIÓN MIDE UC. (2011). Preguntas liberadas pruebas SEPA 2009 – 2010. Recuperado de http://www.sepauc.cl/wp-content/uploads/2014/09/Preguntasliberadas-2009-2010.pdf
CRONBACH, L. J. (1951). Coefficient alpha and the internal structure of tests. Psychometrika, 16(3), 297-334.
Instituto Nacional para la Evaluación de la Educación (INEE).
Instituto Colombiano para la Evaluación de la Educación (ICFES). www.icfes.gov.co
Lawshe, C. H. (1975). A quantitative approach to content validity. Personnel Psychology, 28, 563-575.
Muñiz, J. (1997) Introducción a la teoría de respuesta a los ítems. Madrid: Pirámide.
Martínez Arias, M. R. (1995). Psicometría. Teoría de los tests psicológicos y educativos. Madrid, España: Síntesis.
MESSICK, S. (1995). Standards of validity and the validity of standards in performance asessment. Educational Measurement: Issues and Practice, 14(4), 5-8.
Organización para la Cooperación y Desarrollo Económicos (OCDE). www.oecd.org
Rasch, G. (1960). Probabilistic models for some intelligence and attainment tests. Copenhagen: Danish Institute for Educational Research.
Rasch, G. (1977). On specific objectivity: An attempt at formalizing the request for generality and validity of scientific statements. En M. Glegvad (De.). The Danish Yearbook of Philosophy (pp. 59-94). Copenhagen: Munksgarrd.
Ruiz Bolívar, C. (2002). Instrumentos de Investigación Educativa.
Secretaría de Educación Pública de México (SEP). www.planea.sep.gob.mx
También te puede interesar:
0 comentarios