
¿Qué juicio de valor se puede usar para definir que una prueba carece de confiabilidad? ¿Cuándo podemos decir que goza de validez? ¿Es lo mismo confiabilidad y validez?
En este artículo vamos a explorar los criterios de calidad para la construcción de instrumentos de evaluación y cómo lograr su confiabilidad y validez.
¿Qué es la confiabilidad y qué es la validez en los instrumentos de evaluación?
Para contextualizar, la confiabilidad en términos psicométricos, implica que el instrumento entrega resultados similares cuando se repite su aplicación en las mismas circunstancias y con las mismas personas (Foster, 2017).
La validez por su parte, en términos psicométricos, se entiende de forma más exacta, como la aplicación de una prueba que resulta ser adecuada de acuerdo al lugar donde se aplica. En otras palabras, una prueba es válida si se aplica en estudiantes de primer semestre de Medicina de una facultad, contexto para el que fue creada y realmente mide lo que desea medir, pero se invalida si se aplica en el primer grado de la educación primaria. Aunque sigue siendo confiable, se invalida al no usarse en el contexto adecuado. La validez es una interpretación de los usos que se le dan al instrumento.
Se podría decir entonces que la validez se relaciona más con el instrumento, la confiabilidad con los resultados. Por lo anterior, aunque estemos seguros que una prueba ha sido construida bajo los parámetros de confiabilidad y validez requeridos, siempre se deben tener en cuenta los factores que la pueden afectar al momento de aplicarla y extraer los resultados.
Para controlar esos factores se deben usar herramientas estadísticas que puedan predecir, formular y medir. Además es vital entender que no es igual hablar de la validez y la confiabilidad cuando de las evaluaciones aplicadas en una escuela se trata o cuando hablamos de pruebas censales estandarizadas, ya que el promedio de evaluados, la finalidad de su uso y los reportes (entre otros elementos), varían completamente.
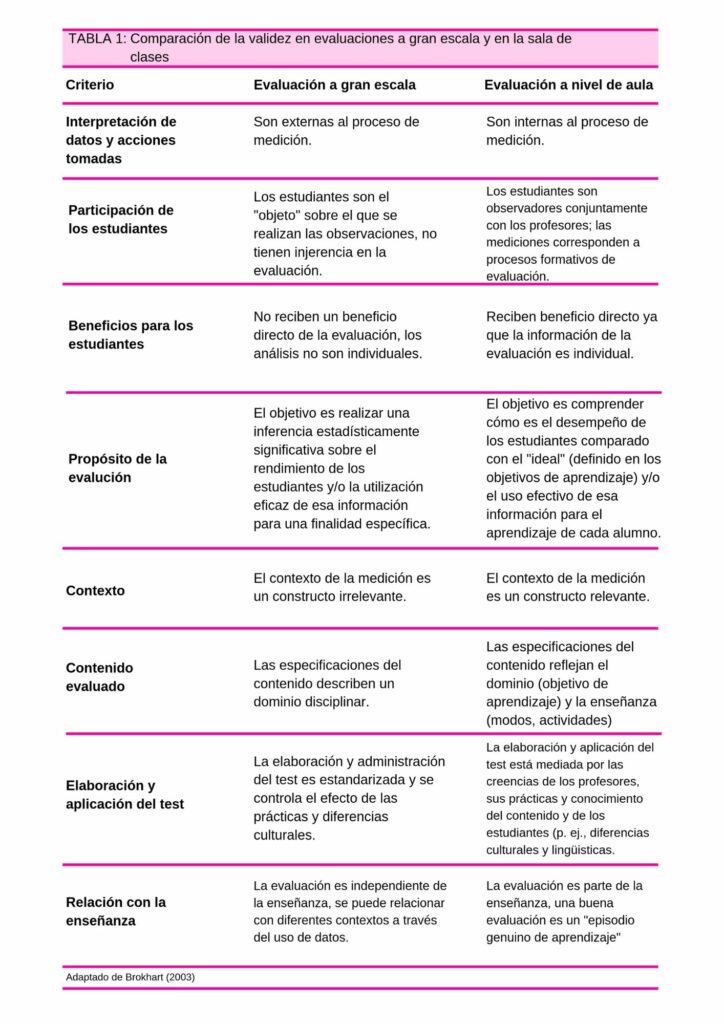
Para explicar mejor, observemos la siguiente tabla tomada de Carla E. Foster, El poder de la Evaluación en el Aula.
¿Ya conoces nuestros cursos?
El ICFES en Colombia al respecto define: “Las evaluaciones que se realizan a través de pruebas estandarizadas deben basarse en instrumentos válidos y confiables; válidos en el sentido que las preguntas de la prueba deben guardar coherencia con los referentes definidos para la evaluación, y confiables en la medida que permitan hacer mediciones sobre lo que se está evaluando. Gracias a estas características es posible hacer inferencias sobre los conocimientos, habilidades y capacidades de las personas evaluadas (Icfes, 2017A)”.
Factores externos asociados a la confiabilidad y la validez
Al construir y aplicar la prueba debemos cuidar factores que pueden afectar la confiabilidad y validez.
1. La improvisación.
2. La falta de validación del instrumento.
3. Adecuación al contexto y la empatía.
4. Condiciones de aplicación (ambientales o de instalaciones).
5. Aspectos mecánicos – técnicos (instrucciones precisas, materiales…).
Vamos a partir de una prueba que ya está construida, que hemos diseñado bajo el DCE (Diseño Centrado en Evidencias). Hemos construido el contexto, la pregunta directa y los distractores. ¿Qué sigue en este proceso?
El primer paso es el juicio de expertos, son personas expertas en la disciplina que está siendo evaluada, quienes revisan la validez de contenidos. Estos contenidos no pueden ser revisados por herramientas estadísticas, si bien existen proyectos de Inteligencia Artificial para lograrlo, por ahora somos los seres humanos los responsables de este primer proceso.
Una recomendación clave cuando se inicia el proceso de construcción de una prueba que aspira a tener validez y confiabilidad es diseñar una alta cantidad de ítems, para ir revisando si son adecuados para el uso, ir ajustando y descartando. Es muy posible que un porcentaje alto de ítems termine siendo eliminado de la prueba real. En el juicio de expertos se ajustarán unos y muy posiblemente se eliminarán muchos otros ítems. Recomendación: construir un 30% más de los ítems requeridos.
Luego, debemos revisar los procedimientos para establecer la confiabilidad. -Medida de confiabilidad: un mismo instrumento aplicado dos o más veces a un mismo grupo.
-Medidas paralelas o formas equivalentes de medir: se aplican dos o más versiones equivalentes de este.
-Método de mitades divididas: se aplica un instrumento una sola vez pero se dividen los ítems, luego se verifican sus resultados.
-Cotejo entre observadores: Son instrumentos de observación y registro, se aplican por dos o más observadores y luego se cotejan los datos.
Validez de contenido

La anterior imagen muestra la realidad de muchas evaluaciones aplicadas en las escuelas o universidades de todo el mundo. Cuando hablamos de validez de contenido, se hace referencia a una propuesta de evaluación que cubra todos los contenidos. Este concepto es controversial, ya que plantea el problema de si debe evaluar todo lo trabajado en clases o si debe evaluar conocimientos, habilidades o competencias que se supone ya deben poseer antes de llegar a determinada clase.
En este sentido toma relevancia la construcción de estándares u objetivos de aprendizaje, que son el punto al cual esperamos el estudiante debe llegar. Y como la evaluación estandarizada no puede contextualizarse a cada escuela, se toma un punto de referencia general al que se espera los estudiantes deben llegar, traducido en Objetivos de Aprendizaje o Estándares. Este proceso a nivel de escuela es más limitado y complejo, ya que las evaluaciones censales carecen de la posibilidad de recoger evidencias que van mas allá de las pruebas de lápiz y papel. Por esta razón siempre se debe tener claridad sobre que tipo de prueba se está construyendo y a que tipo de público se está evaluando.
Para el caso de la escuela, el docente debe garantizar por diversos medios e instrumentos, la recolección de la mayor cantidad de evidencias sobre los contenidos, conocimientos y habilidades más relevantes. Para dar cuenta del logro del objetivo del aprendizaje o del alcance de la competencia.
Podemos nombrar que hay consenso en 4 elementos que caracterizan la validez de contenidos (Sireci, 1998):
1. Definición de un dominio disciplinar.
2. Relevancia de dicho dominio.
3. La representatividad de dicho dominio.
4. Los procedimientos de construcción del instrumento o situación evaluativa.
“Nuestro docente de literatura siempre evalúa con preguntas exactas sobre fechas, nombres o datos demasiado específicos, que si bien pueden ser relevantes, no apuntan al objetivo central de una clase de literatura, esperaríamos nos evalúe nuestra capacidad de interpretación literaria, la calidad de nuestros escritos, nuestro nivel de investigación y conocimientos sobre los contenidos abordados”.
En este ejemplo, si bien la prueba puede en alguna medida verificar unos cuantos conocimientos claves, no genera unas conclusiones válidas, las tareas desarrolladas por los estudiantes para responderla no son de calidad.
No son coherentes con los propósitos del curso. Puede ser que un estudiante obtenga los mejores resultados con esa prueba, pero no existe una directa relación con los objetivos de aprendizaje o las competencias definidas inicialmente. Así como un estudiante puede reprobar, pese a haber alcanzado los objetivos esperados. En este caso no existe ni confiabilidad ni validez.
Análisis Psicométrico de los ítems
Suponemos que ya hemos definido la competencia o el objetivo de aprendizaje de un curso. Ya hemos definido el tipo de evaluación que vamos a implementar, ya hemos revisado con los expertos los ítems.
El siguiente paso en la búsqueda de confiabilidad y la validez de contenido de cada uno de los ítems será que estemos seguros de que cada ítem debe aportar a recoger una o unas evidencias que sumadas dan cuenta del alcance o nivel de aprendizaje. Cada evidencia tiene uno o varios ítems. Por ejemplo miremos este ítem tomado del ICFES:
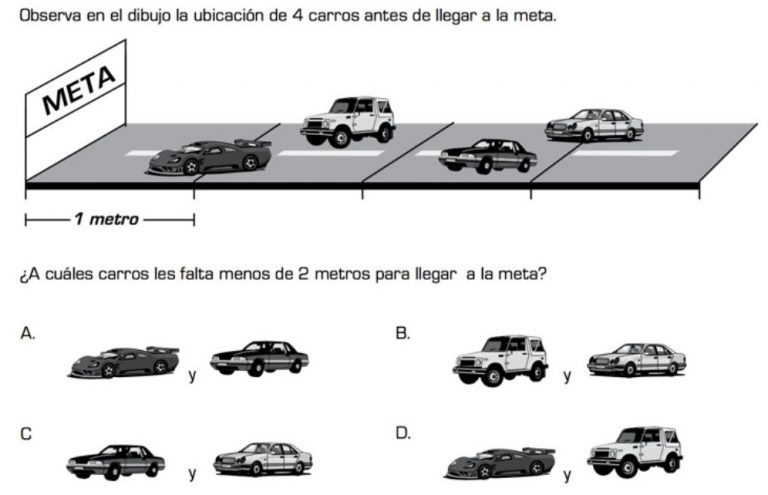
La evidencia que está siendo evaluada en este caso es: El estudiante ubica objetos con base en instrucciones referentes a dirección, distancia y posición (ICFES, 2019).
En este caso, un solo ítem no me va a dar la suficiente información para saber si el estudiante ha alcanzado la evidencia. Se deben aplicar varios ítems similares con la finalidad de:
-Eliminar la posibilidad de respuesta al azar.
-Variar el ítem, su lenguaje y nivel de dificultad.
-Establecer patrones de respuesta.
Vamos a suponer que este ítem va a servir como parte de un instrumento de evaluación estandarizada a nivel nacional. Vamos a observar la tendencia de respuesta de este ítem, para ello podemos recurrir a una forma clásica muy usada llamada TCT (Teoría Clásica de Respuesta de los Test).
“Por medio de la TCT se analiza el comportamiento de los ítems en relación con la proporción de personas que responden correctamente cada pregunta o la proporción de individuos que eligen cada una de las opciones de respuesta del ítem, entre otros indicadores. De igual forma, mide el grado de estabilidad, precisión o consistencia -coeficiente Alpha de Cronbach – del examen para medir la habilidad de los estudiantes (Icfes, 2014); en otras palabras, estima la confiabilidad de las formas, calculando la correlación entre sacar un buen puntaje y la habilidad del estudiante” (ICFES, 2018).
Luego de aplicadas las pruebas, revisamos los resultados definiendo el nivel de complejidad de cada ítem, para esto vamos a usar una regla sencilla:
Ítems que responden acertadamente más del 70% de la población son ítems de nivel bajo.
Ítems que responden acertadamente entre el 30% y el 69% de la población son de nivel medio.
Ítems que responden acertadamente entre el 5% y el 29% de la población son de nivel alto.
Nota: si un ítem lo responde menos del 5% de la población de manera acertada se debe revisar en detalle, puede ser un ítem que sea muy complejo para el contexto o que esté mal diseñado.
Se revisan los distractores para definir el ruido en cada una de las posibles opciones. Los tres distractores deberían tener una similitud a la hora de atraer a los evaluados. Por ejemplo, una prueba donde el 80% marca el distractor A, pero la respuesta correcta era el B, debe ser revisado. Ya que esto se conoce como ruido.
Cuando se revisan los resultados y se extraen los datos, se retiran los registros de personas “sospechosas” que presentaron la prueba siendo sospechosas de copia (resultados extremadamente altos), o de quienes solo presentan una parte de la prueba. O si se han tomado los tiempos, quienes la han terminado en un rango tan bajo que se predice lo han hecho al azar. O a quienes tienen un cuadernillo especial por tener algún tipo de discapacidad cognitiva.
Como ya lo nombramos, si el conocimiento es acumulativo, los resultados también, esto nos permite decidir si alguien ha realizado copias o si existe una correlación negativa (altos resultados y bajos resultados sin correlación). Por ejemplo, un estudiante tiene el mejor promedio en Ciencias Sociales y el peor en Lenguaje cuando es evidente que existe una competencia transversal implícita de lectura. Si realmente no lee bien, no puede responder bien a otras pruebas que así lo requieran. A esto se le conoce como pseudo-azar.
Los resultados por sí solo no nos van a decir mucho, debemos crear unas descripciones cualitativas de lo que sabe y sabe hacer el estudiante (ICFES, 2014). A esto se le ha llamado en Colombia Niveles de Desempeño. Estos niveles de desempeño se construyen en varios escalones que sirven para describir donde están los estudiantes y hasta donde deben llegar. Esa ruta tiene su meta final en el estándar, en Colombia Estándares Básicos de la Competencias (EBC) definidos por el Ministerio de Educación Nacional. Son las metas mínimas a las que cualquier estudiante debería llegar al terminar cada grado de educación.
Si se desea hacer un análisis mucho más complejo (por ejemplo como el que debe hacer el ICFES), se le aplica luego a los ítems la TRI (Teoría de Respuesta al Ítem), la cual estima el comportamiento de cada uno de los ítems, complejidad, discriminación y pseudo azar, partiendo siempre del análisis de la población evaluada, y siendo en este caso más exactos, de cada individuo que presenta la prueba.
En conclusión, este proceso de análisis maximiza la confiabilidad y la validez del instrumento, el cual se aplica en un primer momento en pruebas piloto (tamizajes) y luego en pruebas reales. Si algún ítem en la prueba real no tiene un buen comportamiento se debe sacar del proceso de calificación. Por ejemplo, un ítem que ningún estudiante pueda responder es un ítem que genera ruido y posiblemente su complejidad es superior a la del grupo evaluado. Se puede usar en otro grupo con niveles más altos de formación, ajustarse o eliminarse.
Reiteramos, si partimos de suponer que la adquisición de conocimientos, habilidades y competencias se da de forma acumulativa y sistémica, es sospechoso por ejemplo, encontrar que un estudiante responda acertadamente solo a los ítems que evalúan operaciones aritméticas con números complejos y no a los que evalúan operaciones aritméticas simples o básicas. O que por ejemplo, pueda en un área como Lenguaje, reflexionar a partir de un texto y evaluar su contenido, pero que le sea imposible en el mismo texto comprender los elementos locales que lo conforman.
Para terminar:
Se puede por medio de una rúbrica/rejilla que contenga los datos acá mostrados, extraer la información necesaria. Esto se puede hacer con un método manual.
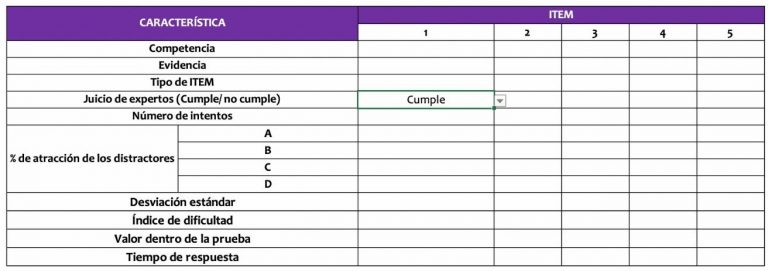
También, se pueden construir sistemas en tablas de Excel que nos puedan generar esta u otras informaciones de acuerdo a las necesidades y contextos. O se puede usar un software, uno de los más conocidos y con código fuente de libre acceso en el Software R, con este podemos incluir las variables, datos, resultados y funciones.
Si las pruebas se aplican con sistemas digitales o plataformas e-learning, Moodle es una muy buena opción. El reto es que para estos últimos tres casos se requiere personal experto que maneje Excel avanzado, o que sepa programar e implementar sistemas, para el caso del Software R, o Moodle.
En los tres casos hay una gran ventaja en contraposición a lo manual, y es que luego de implementado puede usarse en pruebas tanto a nivel de escuela como a gran escala. Como podemos ver, estas herramientas van de menor a mayor complejidad y todo depende de nuestras necesidades.
Por su parte, el personal de diseño deberá responsabilizarse de temas de construcción y revisión de los ítems, juicio de expertos y la toma de decisiones con los resultados obtenidos. Tema del cual hablaremos en nuestro Blog.
¿Deseas aprender a diseñar este tipo de pruebas? no te pierdas nuestro diplomado y cursos.
Escrito por: Eduardo Montoya Castañeda – Director general ESE – Latam.
También te puede interesar
Evaluación para el aprendizaje
Uso de resultados a gran escala
Buenas tardes, con mucho respeto y preocupación, quiero, más que nada hacer una pregunta.
Si en un curso cualquiera, más del 60% de los alumnos y alumnas, reprueba una o mas asignaturas, que factores no se han tomado en cuenta para que, de acuerdo a las políticas educacionales, «todos los alumnos y alumnas aprendan».
Se da el caso que los alumnos y alumnas, son todos sometidos a una evaluación estandarizada, confiable y su validez ha sido aprobada, que los criterios aplicados en la evaluación, son «correctos».
A pesar de todo, un alto porcentaje de los alumnos y alumnas, no logran los porcentajes mínimos de aprobación,
En muchos casos, no es una sola asignatura, son dos o más.
No quiero acusar a nadie, pero si es el mismo docente que imparte ambas asignaturas.
Mi preocupación es que, solo los alumnos y alumnas son medidos o evaluados, a algunos de ellos les puede costar un año de repitencia y es más, puede darse que algunos deserten del sistema por ese factor y cambiar su destino y su vida para siempre.
Si bien es cierto que los alumnos y alumnas deben aprobar, a lo menos el 60%, de los objetivos, mi pregunta es, ¿qué porcentaje de alumnos y alumnas deben «aprender» para que el docente logre «aprobar»?
Con todo el respeto y admiración a quienes han tomado la difícil tarea de formar, educar y enseñar, tanto a niños (as), jóvenes y adultos(as).
Le pido a mis colegas docentes, por soy uno de Uds. con 46 años de servicio en la educación rural
Preocupémonos cuando, no logramos aprendizajes en la gran mayoría de nuestros alumnos y alumnas.
Analicemos nuestras metodologías.
Revisemos nuestras herramientas, medios y métodos de evaluación.
No intentemos ser los dioses de la sala de clases o aula.
Con todo respeto, estimados colegas.
Gracias por tus comentarios Ricardo. La intención real es que los estudiantes aprendan y esto se evidencie en los resultados alcanzados. Que solo un porcentaje apruebe, es un síntoma de algo no funciona muy bien. Pueden ser las estrategias de enseñanza, los niveles de exigencia, la falta de motivación de los estudiantes. Ante todo se trata de hacer análisis profundos y saber tomar decisiones para la mejora de resultados.